資料內(nèi)容:
一、SFT數(shù)據(jù)集如何生成?
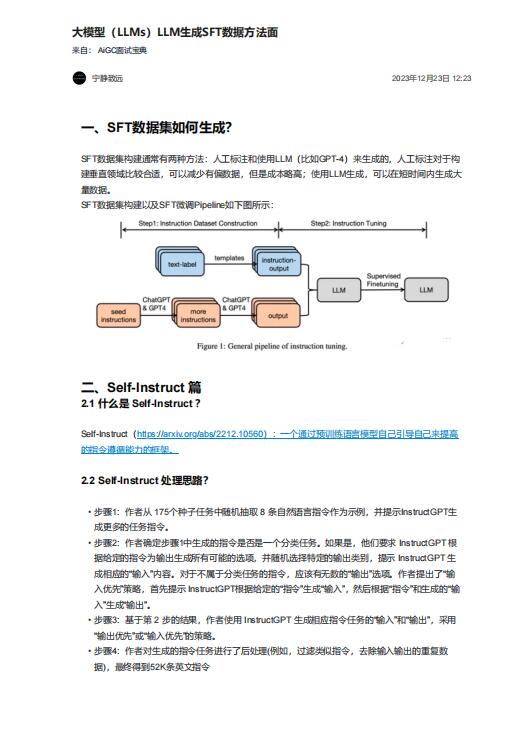
SFT數(shù)據(jù)集構(gòu)建通常有兩種方法:人工標(biāo)注和使用LLM(比如GPT-4)來生成的,人工標(biāo)注對于構(gòu)
建垂直領(lǐng)域比較合適,可以減少有偏數(shù)據(jù),但是成本略高;使用LLM生成,可以在短時間內(nèi)生成大
量數(shù)據(jù)。
二、Self-Instruct 篇
2.1 什么是 Self-Instruct ?
一個通過預(yù)訓(xùn)練語言模型自己引導(dǎo)自己來提高 的指令遵循能力的框架。
2.2 Self-Instruct 處理思路?
• 步驟1:作者從 175個種子任務(wù)中隨機(jī)抽取 8 條自然語言指令作為示例,并提示InstructGPT生
成更多的任務(wù)指令。
• 步驟2:作者確定步驟1中生成的指令是否是一個分類任務(wù)。如果是,他們要求 InstructGPT 根
據(jù)給定的指令為輸出生成所有可能的選項,并隨機(jī)選擇特定的輸出類別,提示 InstructGPT 生
成相應(yīng)的“輸入”內(nèi)容。對于不屬于分類任務(wù)的指令,應(yīng)該有無數(shù)的“輸出”選項。作者提出了“輸
入優(yōu)先”策略,首先提示 InstructGPT根據(jù)給定的“指令”生成“輸入”,然后根據(jù)“指令”和生成的“輸
入”生成“輸出”。
• 步驟3:基于第 2 步的結(jié)果,作者使用 InstructGPT 生成相應(yīng)指令任務(wù)的“輸入”和“輸出”,采用
“輸出優(yōu)先”或“輸入優(yōu)先”的策略。
• 步驟4:作者對生成的指令任務(wù)進(jìn)行了后處理(例如,過濾類似指令,去除輸入輸出的重復(fù)數(shù)
據(jù)),最終得到52K條英文指令

